 March 19, 2026 by Editor |
March 19, 2026 by Editor |
Executing a multilingual town hall for a Multinational Corporation (MNC) across the Asia-Pacific (APAC) region presents a significant technical challenge that transcends simple video conferencing. The requirement is not merely to transmit a video feed; it is to engineer a broadcast-grade production that seamlessly integrates multiple, simultaneous channels of real-time audio interpretation for a geographically dispersed, linguistically diverse audience. This task demands a deep understanding of audio signal flow, video encoding with multiple audio tracks, and resilient distribution infrastructure. For enterprise decision-makers, IT directors, and AV professionals, failing to address this complexity results in disjointed communication, executive messaging being lost in translation, and a compromised return on investment for critical corporate events. The solution lies in a meticulously planned production workflow that treats each language as a discrete, mission-critical data stream, managed from acquisition to playback with precision and redundancy.
This article provides a technical deep dive into the architecture required to successfully produce and stream a multilingual MNC town hall. We will deconstruct the audio infrastructure, the multi-track video encoding process, the distribution strategy using modern streaming protocols, and the critical redundancy measures necessary to guarantee a flawless experience for every participant, regardless of their location or language preference.
Core Audio Infrastructure for Real-Time Interpretation
The foundation of any successful multilingual stream is a robust and impeccably managed audio infrastructure. The primary objective is to acquire clean, isolated audio feeds from the floor (the original speaker) and each interpreter, route them with perfect clarity, and prepare them for embedding into the primary video signal. This process is far more complex than simply connecting a few microphones; it requires a broadcast-level approach to signal management.
Sourcing and Managing Interpreter Audio Feeds
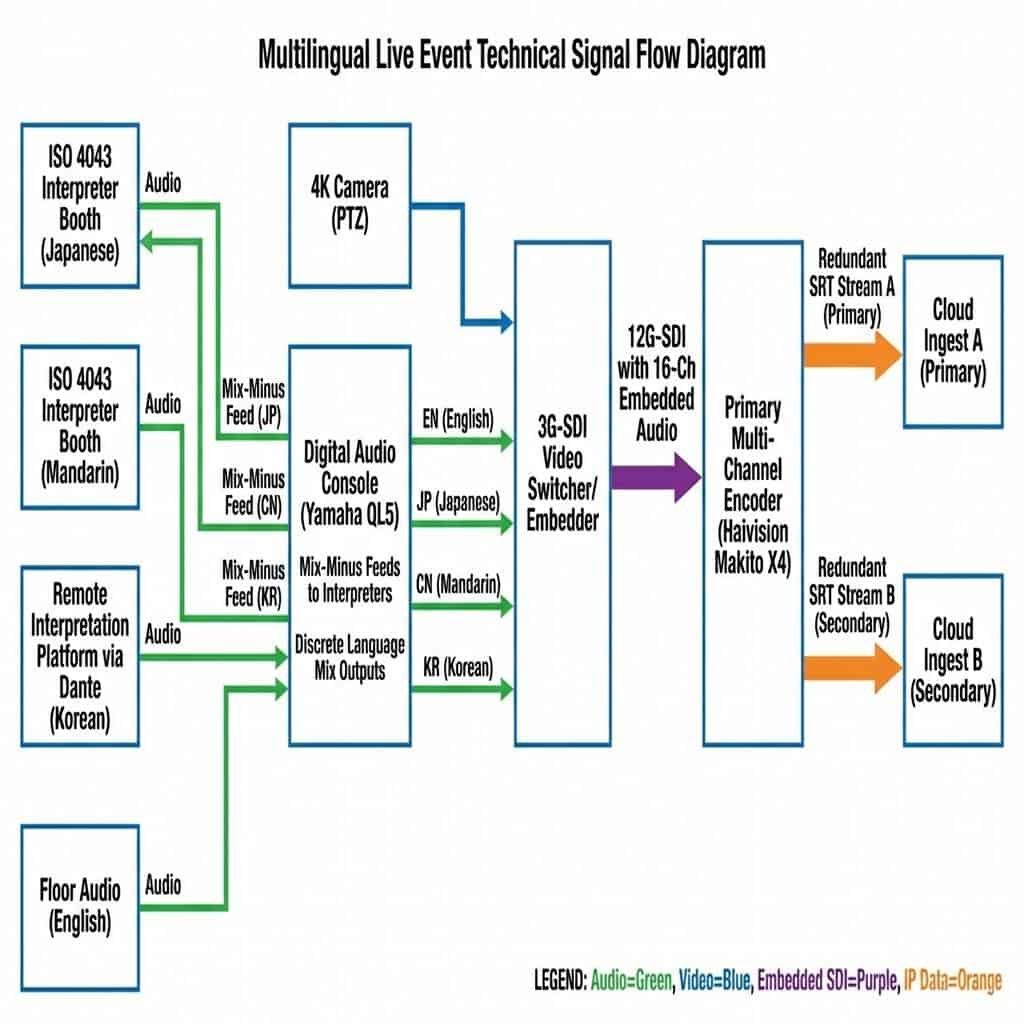
The quality of the final output is directly dependent on the quality of the initial audio capture. Professional interpretation requires a controlled acoustic environment. For on-site events, this is achieved using ISO 4043 compliant, sound-insulated interpreter booths. Each booth is equipped with a professional audio console, high-quality microphones, and talkback systems, allowing interpreters to hear the floor audio (the main speaker’s feed) clearly while their translated output is captured on a completely isolated channel. This isolation is critical to prevent audio bleed and ensure pristine quality for each language track.
For hybrid events with remote interpreters, the audio acquisition shifts to IP-based workflows. Platforms like KUDO, Interprefy, or VoiceBoxer provide broadcast-quality audio streams from certified interpreters working from remote locations. The key technical consideration here is the transport protocol. We leverage Dante (Digital Audio Network Through Ethernet) to manage these feeds. Dante allows for the uncompressed, multi-channel, low-latency routing of audio over a standard Ethernet network. A hardware or software-based Dante controller is used to patch incoming feeds from physical booths or remote IP sources to a central digital audio console. This provides granular control over each individual language stream as if it were a local source.
Advanced Signal Routing and Mix-Minus Configuration
With all audio sources (floor and interpretation channels) terminated in a digital audio console like a Yamaha QL5 or Allen & Heath Avantis, the next step is routing and mixing. A critical technique used is the creation of a mix-minus feed for each interpreter. This is an audio mix that includes the main program (floor) audio minus the interpreter’s own voice, preventing them from hearing a delayed version of their own speech, which can be highly disorienting. Each interpreter receives this custom mix-minus feed to their headset.
Simultaneously, the audio engineer creates a dedicated mix for each language intended for the streaming audience. For the Japanese channel, for example, the engineer will mix the Japanese interpreter’s audio at a primary level (e.g., -6 dBFS) while keeping the floor audio present but “ducked” to a much lower level (e.g., -24 dBFS). This provides context and authenticity without overpowering the translation. Each of these final language mixes (English, Mandarin, Japanese, Korean, etc.) is then output from the console as a discrete audio channel. These discrete channels are then embedded into the video signal, a process we will explore in the next section.
Video Production and Multi-Track Encoding Strategy
Once the discrete audio channels for each language are mixed and ready, they must be synchronized with the primary video program feed and encoded for distribution. This stage involves merging the video and multiple audio streams into a single, cohesive package that can be transmitted efficiently and reliably. The choice of hardware and protocols at this stage is crucial for maintaining quality and ensuring all language options reach the end-user.
SDI and NDI Workflows for Audio Embedding
The professional standard for transporting video within a production environment is the Serial Digital Interface (SDI). A 3G-SDI or 12G-SDI (for 4K/UHD production) signal can carry not only uncompressed video but also up to 16 channels of embedded audio. The discrete language mixes from the audio console are fed into an audio embedder or directly into a video switcher (like a Blackmagic Design ATEM Constellation or Ross Carbonite) that has audio input capabilities. The video switcher operator then maps each language mix to a specific channel within the SDI stream. For example:
- Channel 1: Left Program Audio (Floor)
- Channel 2: Right Program Audio (Floor)
- Channel 3: Japanese Interpretation
- Channel 4: Mandarin Interpretation
- Channel 5: Korean Interpretation
- Channel 6: Bahasa Interpretation
In IP-centric production environments, Network Device Interface (NDI) serves a similar function. An NDI stream can carry a high-quality, low-latency video signal along with multiple channels of audio over a standard 1GbE or 10GbE network. This simplifies cabling but requires a robust, well-managed network infrastructure with sufficient bandwidth and Quality of Service (QoS) configurations to prioritize video and audio traffic.

High-Density Encoding for Multilingual Streams
The single SDI or NDI stream, now containing the main video and all audio tracks, is fed into a professional hardware encoder. This is a critical component; consumer-grade encoders or software solutions often lack the capability to process and encode multiple discrete audio tracks simultaneously. Enterprise-grade encoders from manufacturers like Haivision (Makito X4), Elemental (AWS Elemental Live), or AJA (HELO Plus) are specifically designed for this task. The encoder is configured to create a single video ladder (e.g., 1080p, 720p, 540p) using an H.264 (AVC) or H.265 (HEVC) codec. Crucially, it is also configured to ingest all the embedded audio tracks and encode each one as a separate audio stream within the final transport stream. This creates a single outgoing stream package that contains one video track and multiple selectable audio tracks, all perfectly synchronized.
Distribution Architecture and Player-Side Experience
Encoding is only half the battle. The multi-track stream must be delivered reliably across the diverse network conditions of the APAC region and presented to the viewer in a way that allows for easy language selection. This requires a robust transport protocol, a global Content Delivery Network (CDN), and an intelligent video player.
SRT Contribution and HLS/DASH Distribution
For the first-mile contribution from the event venue to the cloud ingest point, the Secure Reliable Transport (SRT) protocol is the industry standard. SRT provides the reliability of TCP-based protocols with the low latency of UDP, recovering from packet loss and navigating unpredictable networks, which is essential when streaming from corporate offices or hotels. The multi-track stream is sent via SRT to a cloud-based media server or directly to the CDN’s ingest point.
For the final delivery to viewers (the last mile), HTTP-based adaptive bitrate protocols are used. HTTP Live Streaming (HLS) and Dynamic Adaptive Streaming over HTTP (MPEG-DASH) are the two prevailing standards. The media server transmuxes the incoming SRT stream into HLS and DASH formats. These protocols segment the video and audio into small chunks that can be delivered over standard web servers. A manifest file (an .m3u8 playlist for HLS) is generated, which acts as a table of contents for the player. This manifest file explicitly lists all available video bitrates and, most importantly, all available audio language tracks, allowing the player to present these options to the user.
The Enterprise Video Player and Language Selection
The final user experience hinges on the video player. An enterprise video platform (EVP) like Brightcove, Kaltura, or a custom-built player using video.js or THEOplayer is required. The player parses the HLS or DASH manifest file and automatically detects the presence of multiple audio tracks. It then dynamically populates a user interface element, typically a settings cog or a dedicated “Audio” button, with the list of available languages. When a user in Tokyo selects “Japanese” from the dropdown menu, the player seamlessly switches to fetching the Japanese audio segments without interrupting or re-buffering the video. This client-side functionality is the culmination of the entire production chain, delivering a tailored, accessible experience to each member of the global audience.
Ensuring Redundancy and Quality of Service
For a mission-critical MNC town hall, failure is not an option. A comprehensive redundancy and failover strategy must be built into every layer of the architecture, from the on-site hardware to the global distribution network. This ensures high availability and maintains Quality of Service (QoS) throughout the event.
Hardware and Network Path Redundancy
On-site, a 1+1 redundancy model is the minimum standard for critical hardware. This means running a fully parallel, secondary chain of equipment: a second video switcher, a second audio console, and a second primary encoder. In the event of a failure in the primary encoder, the signal path can be switched to the backup unit instantly. Network connectivity from the venue is fortified using network bonding technology. Devices from Peplink or LiveU combine multiple internet connections (e.g., two dedicated fiber lines, a 5G cellular link, and a satellite backup) into a single, highly resilient data pipe. If one connection degrades or fails, traffic is automatically rerouted over the remaining active connections, ensuring the SRT contribution stream is never interrupted.
Geo-Redundant Cloud and CDN Architecture
Redundancy extends into the cloud infrastructure. The primary SRT stream from the venue should be sent to two geographically separate cloud ingest points (e.g., AWS us-east-1 and ap-southeast-1). If one region experiences an issue, the CDN can pull from the healthy secondary ingest point. A top-tier CDN with a strong presence in the APAC region, such as Akamai or AWS CloudFront, is essential. These CDNs operate thousands of Points of Presence (PoPs) globally. When a user in Seoul requests the stream, the CDN automatically serves the video and audio chunks from the nearest PoP, minimizing latency and buffering. This distributed architecture also provides immense scalability, ensuring that tens of thousands of simultaneous viewers can access the stream without degrading performance for anyone.
In conclusion, managing a multilingual MNC town hall in the APAC region is a complex broadcast engineering task that demands meticulous planning and execution. It requires a holistic approach that begins with pristine audio acquisition, moves through a precise multi-track encoding workflow, and concludes with a resilient, geo-redundant distribution strategy. By integrating professional audio infrastructure, broadcast-grade video hardware, and intelligent streaming protocols, organizations can transcend language barriers and deliver clear, impactful communication to their entire global workforce. This level of technical execution is the hallmark of a professional B2B streaming solution, ensuring that every voice is heard, and every message is understood.